Recently, I was assigned to build an RAG system to mitigate LLM’s hallucination on proprietary documents. I can take advantage of the given pre-trained BERT/Roberta models and an API towards a gte model as an encoding service as project resources. Therefore, I don’t need to build the system from scratch. Here’s something I learned from this project from obstacles and my decisions.
RAG, a bird’s-eye view.
Let’s quickly review RAG for those who did not get acquainted with it. If you already know about it, skip this section.
RAG, Retrieval Augmented Generation, is a practical approach to alleviate the hallucination problem of LLM. Hallucination means a status when LLM cannot respond to users’ input correctly, even concoct misinformation in a severe tone. This usually happens when LLM meet a problem which does not exist in its training dataset. RAG fixes this problem by furnishing the LLM with relevant information as prompts embedded into the user’s input prompts. This was first formulated in (Jiang et al., 2023) by a team whose members are from Facebook, UCL, and NYU. The name of RAG indicates that the system comprises three components (or processes): Retrieval, Augmentation, and Generation. Making each part happens can produce an LLM, which tells jargon.
The experience from this project proved that three major obstacles existed in the three parts mentioned above. A poor retriever or information retrieval (IR) system in RAG causes the misinformation kept. Inefficient directions injected into user’s prompts make the LLM output below expectations. Furthermore, an LLM that does not have enough tokens tolerance may refuse long augmented texts or ignore important prompts regardless of the role of prompts (user/system/assistant). Therefore, the primary mission of a well-functioning RAG system is to tune each part to work satisfactorily.
Decision: Do we need LangChain?
LangChain is a framework that consists of all the useful components of RAG. This framework is well-known of high compatibility of each choice. For example, for vector storage, some choices like Faiss and Chroma are both supported by LangChain. Do we need it to facilitate the RAG development?
YES: LangChain is useful.
In the retrieval part, long texts are unavailable as input in popular Embedding models like BERT/RoBerta. It is required to slice these tokens into acceptable lengths. When transforming texts to tokens, the output lengths are unpredictable because some words out of token/id maps will be decomposed to sub-words, i.e. one word might be several tokens in the output. Without a specified length, we don’t know the length of chunks. An effective way to address this issue is to tokenize the texts and then experimentally obtain the output length. Then, we need to tokenize the texts again. Programmatically, it is quite costly to finish this function in my project because I don’t have enough time. In this scenario, LangChain can help. LangChain provides a RecursiveTextSplitter to deal with the chunks without extra effort.
And No: LangChain is complicated.
Compatibility is an asset; however, it is not taken for granted. Taking the vector storage we mentioned before as an example. Actually, we will choose only one vector database, but LangChain has to do more abstract and decoupling for different choices. This kind of work makes the tracing stack deeper and costs the developer more debugging time. And in this procedure, LangChain introduces many third-party dependencies which may be helpful for LangChain but not necessarily helps easy RAG implementation. Pydantic restricts the types of function parameters, which enables Python to have some features like static language. It is adopted in LangChain LLM parts, but it is unnecessary if you write this part on your own. All in all, we are used to regard Python as a dynamic language, and it does.
So, how do we make the decision? Luckily, components in LangChain are provided loosely. We have choices to decide which part helps and which doesn’t. The conclusion is simple: we can use LangChain selectively.
Obstacle: Poor retrieval performance
Information Retrieval has been long discussed in NLP academia. It should have been a refined module. But in this project, it is an obstacle. Fine-tuning has not done perfectly which causes the performance lower than expectation. I opted for a gte Embedding API as an expediency, but it still failed to satisfy the users’ requirements.
The idea behind modern Information Retrieval systems is explicit: transform documents and queries into dense vector representations (Embeddings) and calculate cosine similarity between document embeddings and query embedding. The most popular model is BERT. It is a typical model that requires two-stage training, pre-training and fine-tuning, called transfer learning. Although there are some models with a huge number of parameters pre-trained on larger training datasets, these models’ performance is not good in proprietary documents because jargon of internal files is not common in public texts, and the relationships among different jargon are impossible to be learned from public datasets. So, we need fine-tuning.
In retrieval parts, there are always two or even four steps, called initial retrieval (IR, recall) and re-ranking (RR). This is the requirement of trading-off between speed and accuracy (Zhao et al., 2022). They also use the embedding model in different ways. In the IR stage, dual encoders (here, we take BERT or Roberta) independently encode queries and documents. In contrast, query and document are concatenated in the RR stage when fed into the model. IR calculates the similarities between two embeddings acquired from two encoders with a faster speed but low ranking performance. This step leaves as many relevant documents as possible. RR calculates the similarities in filtered options by feeding the first position logit in the output into a similarity function, which is slower than IR but works better in ranking. In this project, we focus on the initial retrieval.
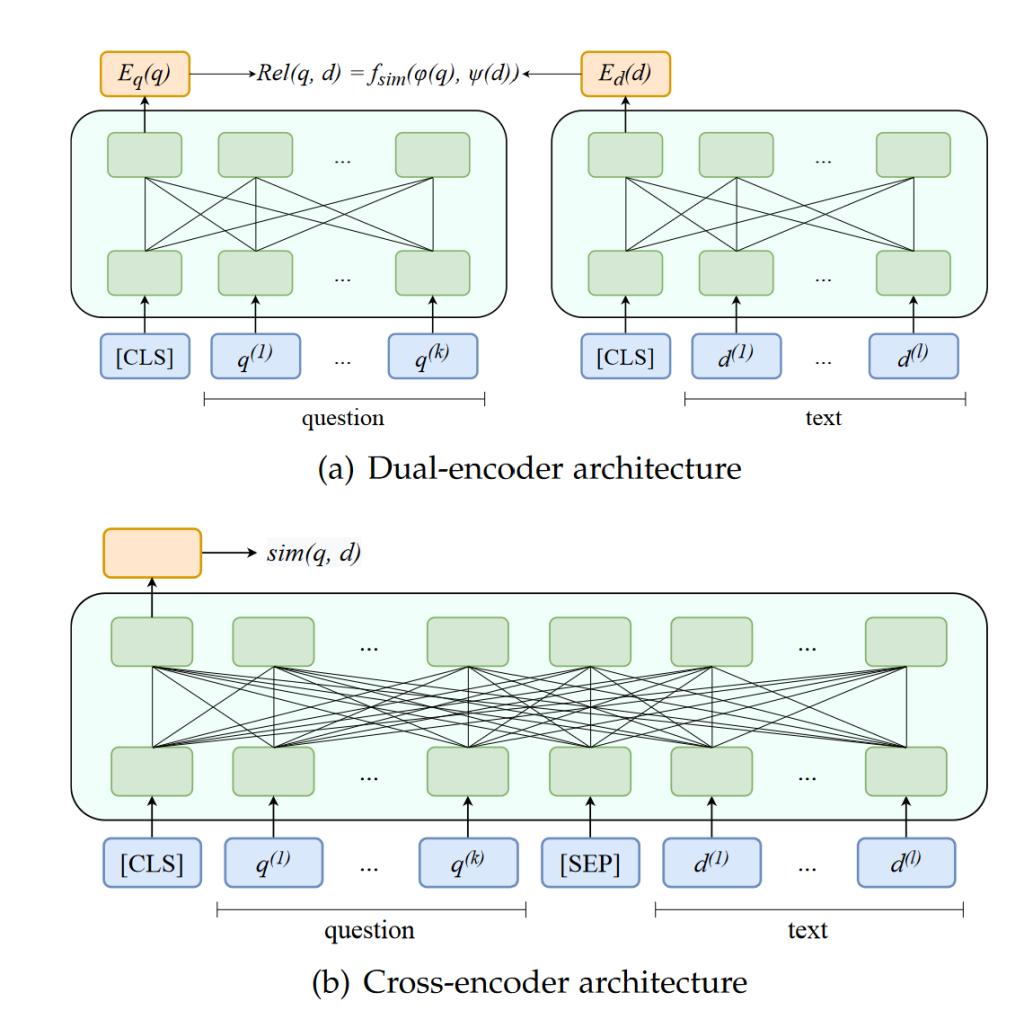
Figure 1 Roles of encoders in different steps in Information Retrieval (Zhao et al., 2022)
This project has yet to yield a satisfactory result in fine-tuning the model. The possible reason for this obstacle is an unbalanced dataset. In the training dataset, long documents take far more records than short documents after chunking, which means one query may be mapped to a single document many times by a cartesian product between the query and chunked documents. It should be avoided.
Obstacle: Wayward Large Language Models
LLM is fantastic but not as bright as people expected when implemented in context. Obviously, prompts don’t work sometimes. For example, when we want to set a length limit for the response, we tell the LLM not to exceed your response beyond a number. However, it doesn’t work. ChatGPT can make it. But others failed.
LLM also fails to identify the relevance of the given documents. This is a trendy endeavour in Recommendation Systems studies, but it failed in our experiments. Sure, there are some ways to improve, such as multi-hop (Khalifa et al., 2023) or pairwise ranking prompting (Qin et al., 2024). Nevertheless, we haven’t conducted experiments on this novel approach.
Reference
Jiang, Z., Xu, F. F., Gao, L., Sun, Z., Liu, Q., Dwivedi-Yu, J., Yang, Y., Callan, J., & Neubig, G. (2023). Active Retrieval Augmented Generation (arXiv:2305.06983). arXiv. http://arxiv.org/abs/2305.06983
Khalifa, M., Logeswaran, L., Lee, M., Lee, H., & Wang, L. (2023). Few-shot Reranking for Multi-hop QA via Language Model Prompting (arXiv:2205.12650). arXiv. http://arxiv.org/abs/2205.12650
Qin, Z., Jagerman, R., Hui, K., Zhuang, H., Wu, J., Yan, L., Shen, J., Liu, T., Liu, J., Metzler, D., Wang, X., & Bendersky, M. (2024). Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting (arXiv:2306.17563). arXiv. http://arxiv.org/abs/2306.17563
Zhao, W. X., Liu, J., Ren, R., & Wen, J.-R. (2022). Dense Text Retrieval based on Pretrained Language Models: A Survey (arXiv:2211.14876). arXiv. http://arxiv.org/abs/2211.14876
Leave a Reply